7주차(3.13 ~ 3.17) 일정
| Week | 날짜 | 요일 | 주제 | 카테고리 |
| 7주차 | 3/13 | 월 | 시각지능 딥러닝 | Computer Vision / CNN |
| 7주차 | 3/14 | 화 | 시각지능 딥러닝 | LeNet / AlexNet / VGGNet |
| 7주차 | 3/15 | 수 | 시각지능 딥러닝 | Transfer Learning / Data Augmentation |
| 7주차 | 3/16 | 목 | 시각지능 딥러닝 | Object Detection |
| 7주차 | 3/17 | 금 | 시각지능 딥러닝 | Object Detection |
3/13(월) ┃ Computer Vision & CNN
1) Computer Vision
- 인간이 눈으로 세상을 바라보듯 컴퓨터에게도 이미지나 동영상 등의 시각적인 정보를 인식하고 처리할 수 있는 능력을 갖도록 연구/개발하는 AI 분야이다
- 기존에는 미분을 통한 Edge Detection 등 여러가지 Rule Based 한 시도들을 많이 했지만, 시각적인 정보에는 너무나 많은 변수와 상황들이 존재하기에 한계가 있었다
- Deep Learning과 CNN 을 통해 급속도로 성장함
- Object Detection, Semantic Segmentation, Image Classification, Action Classification, Captioning
2) Convolutional Neural Network (CNN, 합성곱 인공신경망)


- 합성곱 신경망(Convolutional neural network, CNN)은 시각적 이미지, 영상을 분석하는 데 사용되는 다층의 피드-포워드적인 인공신경망의 한 종류이다
- 일반적으로 Convolutional layer, Pooling layer, Fully-connected layer로 구성된다
- Convolutional layer에서는 입력 이미지에서 특징(feature)을 추출하기 위해 필터(filter)를 사용하여 합성곱(convolution)을 수행한다
- 이렇게 추출된 특징은 Pooling layer에서 간단한 연산을 통해 축소된다
- 마지막으로, Fully-connected layer에서는 이러한 특징을 이용하여 분류, 예측 또는 회귀와 같은 작업을 수행한다
- 이러한 CNN의 구조는 이미지 내에서 특징을 추출하고, 공간적 위치 정보를 보존하면서 이미지를 분류하거나 예측하는 데 강점을 보인다
3/14(화) ┃ LeNet / AlexNet / VGGNet
1) LeNet

- 1990년에 CNN 개념을 최초로 개발한 Yann LeCun 의 CNN architecture
- 이후로 계속 개선하여 최종적으로 1998년에 LeNet-5를 발표
- LeNet-5에서는 입력 이미지의 크기가 커졌고, Fully connected layer가 추가, Parameter 수는 6만개에 달한다 (DNN: 약 12만개, LeNet-1: 약 3천개)
2) AlexNet

- 2012년, ImageNet에서 우승한 CNN 아키텍처의 딥러닝 모델
- AlexNet은 5개의 Convolutional layer와 3개의 Fully-connected layer로 이루어짐
- 이전의 모델들과는 달리 ReLU(Rectified Linear Unit) 함수를 활성화 함수로 사용하여, 학습 속도를 높이고 모델 성능을 개선함
- 또한, Data Augmentation 기법을 사용하여 데이터를 증강하고, Overfitting 문제를 해결함
3) VGGNet
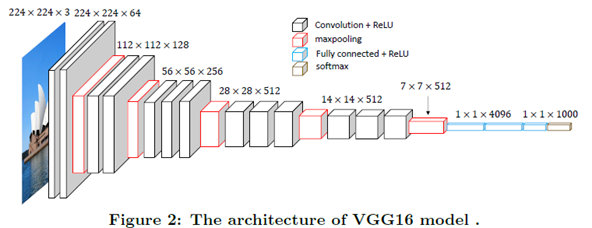
- 2014년, ImageNet에서 2위를 차지한 CNN 아키텍처의 딥러닝 모델
- AlexNet과 유사한 구조를 가지고 있으며, Convolutional layer를 깊게 쌓아서 학습하는 것이 특징
- VGGnet은 16개 또는 19개의 layer를 가지고 있으며, 이를 VGG-16 또는 VGG-19 이라고 부름
- 3x3 크기의 작은 필터를 사용하여 conv layer를 깊게 쌓은 구조
- Pre-training 기술을 사용하여 학습속도를 높일 수 있도록 개발
3/15(수) ┃ Data Augmentation & Transfer Learning
1) Data Augmentation (데이터 증강)
- 데이터셋의 양이 적을 때, 기존의 데이터를 다양한 방식으로 변형하여 데이터셋의 크기를 증강시키는 기법
- 좌우 반전, 회전, 크기 조절, 색상 변환 등
- tf.keras.preprocessing.image.ImageDataGenerator 라이브러리 사용
2) Transfer Learning & Fine-tuning
- 기존에 학습된 모델의 일부 또는 전체를 가져와 새로운 모델 학습에 재사용하는 기법
- https://keras.io/api/applications 모델 참고

학습할 데이터셋의 크기와 해당 데이터셋이 pre-trained model이 기존에 학습한 데이터셋과 얼마나 유사한지에 따라 Fine-tuning 전략이 달라진다
- 우리 데이터셋이 크고, 유사성이 작다.
- 모델 전체를 학습시키는 것이 낫다. 데이터셋의 크기가 크기 때문에 충분히 학습이 가능하다. 데이터셋끼리의 유사성이 작다고 해도 모델의 구조와 파라미터들은 여전히 재사용 가능하므로, 재학습을 시켜주는 편이 낫다.
- 우리 데이터셋이 크고, 유사성이 크다.
- Convolution base의 뒷부분과 Classifier를 학습시킨다. 사실 최적의 경우이기 때문에 모든 옵션을 선택할 수 있지만, 데이터셋이 유사하기 때문에 전체를 학습시키기보다는 강한 feature가 나타나는 Convolution base의 뒷부분과 Classifier만 새로 학습시키는 것이 최적이다.
- 우리 데이터셋이 작고, 유사성이 작다.
- Convolution base의 일부분과 Classifier를 학습시킨다. 가장 나쁜 상황으로, 제일 어렵다. 데이터가 적기 때문에, 적은 레이어를 Fine tuning하면 별 효과가 없고, 많은 레이어를 Fine tuning했다가는 오버피팅이 발생할 것이다. 따라서 Convolution base의 어느 정도를 새로 학습시켜야 할지를 적당히 잡아주어야 한다.
- 우리 데이터셋이 작고, 유사성이 크다.
- Classifier만 학습시킨다. 데이터가 적기 때문에 많은 레이어를 Fine tuning할 경우 오버피팅이 발생한다. 따라서 앞부분의 Feature Extraction은 그대로 쓰고, 최종 Classifier의 FC Layer들에 대해서만 Fine tuning을 진행한다.
그리고 앞부분의 Convolution base를 재학습시키는 경우에는 미리 학습된 가중치를 잊지 않으면서도 추가로 학습을 해 나갈 수 있도록 learning rate(lr)을 작게 잡아주는 것이 바람직하다.
TIL: (CNN에서의) Transfer Learning과 Fine Tuning
미리 학습된 모델을 갖다 쓰는 것
driip.me
3/16(목) ~ 3/17(금) ┃ Object Detection
1) Object Detection
- 이미지에 나타나는 여러 개의 Object 위치와 종류를 찾아내는 기술이다
- Object Detection = Multi-Labeled Classification + Bounding Box Regression
- Datasets: PASCAL VOC -> ImageNet -> COCO
- Object Detection Metrics: NMS(Non Maximum Suppression), mAP(mean Aveage Precision)
2) YOLO v3
- YOLO is Unified, real-time object detection
- 2015년 YOLO v1 을 시작으로 2023년 현재 YOLO v8 released
- pre-trained 된 모델의 가중치를 활용하여 실습해보기
- Github Ultralytics YOLO v3
- Ultralytics YOLO v8 Docs
- Redmon, J., & Farhadi, A. (2015). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779-788).
- Redmon, J., & Farhadi, A. (2016). YOLO9000: Better, faster, stronger. In Proceedings
- [Paper Review] You Only Look Once : Unified, Real-Time Object Detection by 고려대학교 산업경영공학부 DSBA 연구실
- [Paper Review] YOLO9000: Better, Faster, Stronger by 고려대학교 산업경영공학부 DSBA 연구실
'5. 활동 > KT AIVLE AI 3기' 카테고리의 다른 글
| KT AIVLE AI 3기 ┃ 11주차(4.10 ~ 4.14) - 미니 프로젝트 5차 (0) | 2023.04.10 |
|---|---|
| KT AIVLE AI 3기 ┃ 8주차(3.20 ~ 3.24) - 미니 프로젝트 3차 (0) | 2023.03.21 |
| KT AIVLE AI 3기 ┃ 6주차(3.6 ~ 3.10) - 미니 프로젝트 4차 (0) | 2023.03.07 |
| KT AIVLE AI 3기 ┃ 5주차(2.27 ~ 3.3) - Deep Learning (0) | 2023.02.27 |
| KT AIVLE AI 3기 ┃ 4주차(2.20 ~ 2.24) - Machine Learning (0) | 2023.02.27 |
댓글