5. 활동/KT AIVLE AI 3기
KT AIVLE AI 3기 ┃ 4주차(2.20 ~ 2.24) - Machine Learning
로기(dev-loggi)
2023. 2. 27. 10:41
4주차(2.20 ~ 2.24) 일정
| 날짜 | 주제 | 카테고리 |
| 2/20 | 머신러닝 | 머신러닝 개요 |
| 2/21 | 머신러닝 | 회귀/분류 모델, 성능 평가 방법 |
| 2/22 | 머신러닝 | 머신러닝 알고리즘 |
| 2/23 | 머신러닝 | K 분할 교차 검증 |
| 2/24 | 머신러닝 | 앙상블, 성능 최적화 |
2/20(월) ┃ 머신러닝 개요
머신러닝 개요
- 지도 학습 vs 비지도 학습 vs 강화 학습
- 분류 vs 회귀 vs 클러스터링
- 독립변수(row, x, feature), 종속변수(column, y, target)
- 오차
- 데이터 분리(train/valid/test)
- Overfitting, Underfitting
- 라이브러리 - Scikit-Learn
2/21(화) ┃ 머신러닝 개요
성능 평가
- 회귀 모델 평가 지표 - MSE, RMSE, MAE, MAPE, R-Squared
- 분류 모델 평가 지표 - Confusion Matrix(TN, FP, FN, TP), Accuracy, Precision(정밀도), Recall(재현율, 민감도), Specificity(특이도), F1-Score
2/22(수) ┃ 머신러닝 알고리즘
Linear Regression (선형 회귀)
- 회귀
- 회귀식을 통해 오차를 줄여나가는 방식으로 가중치를 구함
K-Nearest Neighbor (K 근접 이웃)
- 회귀/분류
- 회귀: k개 값의 평균을 계산하여 값을 예측
- 분류: 가장 많이 포함된 유형으로 분류
- 데이터 분포의 영향을 받으므로 Scaling 필수
Decision Tree (의사결정트리)
- 회귀/분류
- 불순도(Impurity) - 지니 불순도, 엔트로피
- 정보 이득
- 변수 중요도
- 하이퍼파라미터
- max_depth
- min_samples_split
- min_samples_leaf
- max_feature
- max_leaf_node
Logistic Regression (로지스틱 회귀)
- 분류
- 분류 문제를 회귀식으로 푼다
- 로지스틱 함수를 통해 확률로 해석하여 분류
- 이진 분류는 sigmoid 함수, 다중 분류는 softmax 함수
SVM(Support Vector Machine)
- 회귀/분류
- 서포트 벡터를 찾아서 결정 경계선을 찾는 알고리즘
- SVM 성능을 높이기 위해 정규화 작업 필요
- 결정 경계(Decision Boundary)
- 서로 다른 분류값을 결정하는 경계
- 벡터(Vector)
- 2차원 공간 상에서 나타나는 데이터 포인트
- 서포트 벡터(Support Vector)
- 결정 경계선과 가장 가까운 데이터 포인트
- 마진(Margin)
- 서포트 벡터와 결정 경계 사이의 거리
- 마진을 최대로 하는 결정 경계를 찾는 것이 SVM의 목표
- 마진이 클수록 새로운 데이터에 대해 안정적으로 분류할 가능성이 높음
- Cost
- SVM 모델에서 오차를 어느 정도 허용할지를 결정하는 파라미터
- Cost값이 커지면 마진이 작아져 에러를 감소시키는 결정 경계선을 만듦(Hard Margin) -> Over Fitting
- Cost값이 작아지면 마진이 커져 에러를 증가시키는 결정 경계선을 만듦(Soft Margin) -> Under Fitting
- Gamma
- SVM 모델에서 결정 경계선의 유연성을 조절하는 파라미터
- Gamma값이 클수록 작은 표준편차를 가져, 데이터 포인트가 행사하는 영향력이 줄어듦 -> Over Fitting
- Gamma값이 작을수록 큰 표준편차를 가져, 데이터 포인트가 행사하는 영향력이 길어짐 -> Under Fitting
2/23(목) ┃ K-Fold Cross Validation
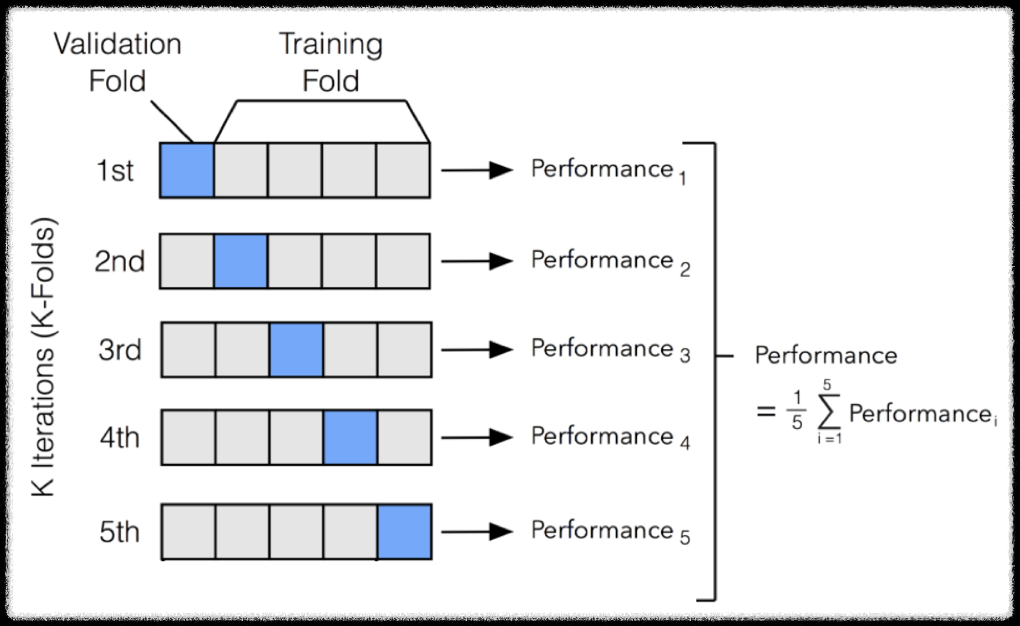
- 모든 데이터가 평가에 한 번, 학습에 k-1번 사용
- k개의 분할(Fold)에 대한 모든 학습 평가 추정치 -> 평균, 표준편차 계산
- Under Fitting, 데이터의 편향 방지
2/24(금) ┃ Ensemble & Hyperparameter Tuning
앙상블(Ensemble)
- Voting
- 여러 개의 모델 예측 결과에 투표를 통해 결정하는 방식
- Hard Voting(다수결), Soft Voting(확률로 계산하여 최댓값)
- Bagging
- 여러 개의 같은 알고리즘에 대한 예측 결과를 Voting으로 결정
- 데이터를 랜덤 복원 샘플링하여 병렬 학습
- Bagging의 대표적인 알고리즘 RandomForest
- Boosting
- 여러 개의 같은 알고리즘을 순차적으로 학습
- 이전 모델의 예측이 틀린 데이터에 대해 올바르게 예측할 수 있도록 다음 모델에게 가중치(Weight)를 부여하면서 학습과 예측을 진행
- 배깅에 비해 높은 예측 성능을 자랑하지만, 속도가 느리고 과적합 발생 가능성이 있음
- 대표적인 부스팅 모델: XGBoost, LightBGM
- Stacking
- 여러 모델의 예측 값을 최종 모델의 학습 데이터로 사용하여 예측하는 방법
ex) KNN, LR, XGB 학습 및 예측 -> RandomForest 학습 - 현실에서 많이 사용되지 않음
- 여러 모델의 예측 값을 최종 모델의 학습 데이터로 사용하여 예측하는 방법
RandomForest
- Bagging의 가장 대표적인 알고리즘
- 여러 Decision Tree 모델이 전체 데이터에서 Bagging으로 각자의 데이터 샘플링
- 모델들이 개별적으로 학습을 수행한 뒤 모든 결과를 집계하여 최종 결과를 결정
- 주요 Hyperparameters
- n_estimators: 트리 개수
- max_depth: 트리의 최대 깊이
- min_samples_split: 노드를 분할하기 위한 최소 샘플 수
- min_samples_leaf: 리프 노드가 되기 위한 최소 샘플 수
- max_feature: 최대 feature 수
- n_jobs: cpu 몇 개 사용할지
XGBoost(eXtreme Gradient Bossting)
- 회귀/분류
- 부스팅 모델 GBM을 병렬 학습 가능하도록 만든 모델이 XGBoost
- 높은 예측 성능, 과적합 규제(Regularization), 교차 검증, 결측치 자체 처리(use_missing 옵션)
- 주요 Hyperparameters
- learning_rate: 0~1사이 값
- n_estimators: weak learner 개수, 많을수록 일정 수준까지 성능이 좋지만 학습 시간이 길어짐
- min_child_weight: 트리에서 추가적으로 분할할 지를 결정하기 위해 필요한 데이터들의 weight 총합, 값이 클수록 분할을 자제함(기본값=1)
- gamma: 트리에서 추가적으로 분할할 지를 결정하기 위해 필요한 최소 손실 감소 값, 이 값보다 큰 손실이 감소된 경우에 분할함, 값이 클수록 Over Fitting 위험 감소(기본값=0)
- max_depth: 트리의 최대 깊이
- sub_sample: weak learner가 학습에 사용하는 데이터 샘플링 비율, 과적합이 염려되는 경우 1보다 작은 값 설정(기본값=1, 전체 데이터 기반 학습)
- colsample_bytree: 트리 생성에 필요한 Feature 샘플링 비율. Feature가 많은 경우 과적합을 조절하기 위해 사용(기본값=1, 모든 Feature 사용)
- reg_lambda: L2 규제 적용 값. Feature가 많은 경우 이 값을 키워 과적합 방지(기본값=1)
- reg_alpha: L1 규제 적용 값. Feature가 많은 경우 이 값을 키워 과적합 방지(기본값=0)
Hyperparameter Tuning
- Random Search: 표본 조사
- Grid Search: 전수 조사